
1. torch.utils.data
1.1 torch.utils.data.DataLoader类
是加载数据的核心,返回可迭代数据。
1 | class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None) |
是一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集。在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。做到一个数据的初始化。
1 | ''' |
1.2 torch.utils.data.Dataset类
创建数据集,有_getitem_(self,index)函数来根据索引序号来获取图片和标签,有len(self)函数来获取数据集的长度。其他的数据集类必须是其子类,要继承它的特性。
我们如果要自定义自己数据读取的方法,就需要继承torch.utils.data.Dataset,并将其封装到DataLoader中。torch.utils.data.Dataset表示该数据集,继承该类可以重载其中的方法,实现多种数据读取及数据预处理的方式。TensorDataset()方法可以将tensor数据装载进入称为dataset
1 | from torch.utils.data import DataLoader,Dataset |
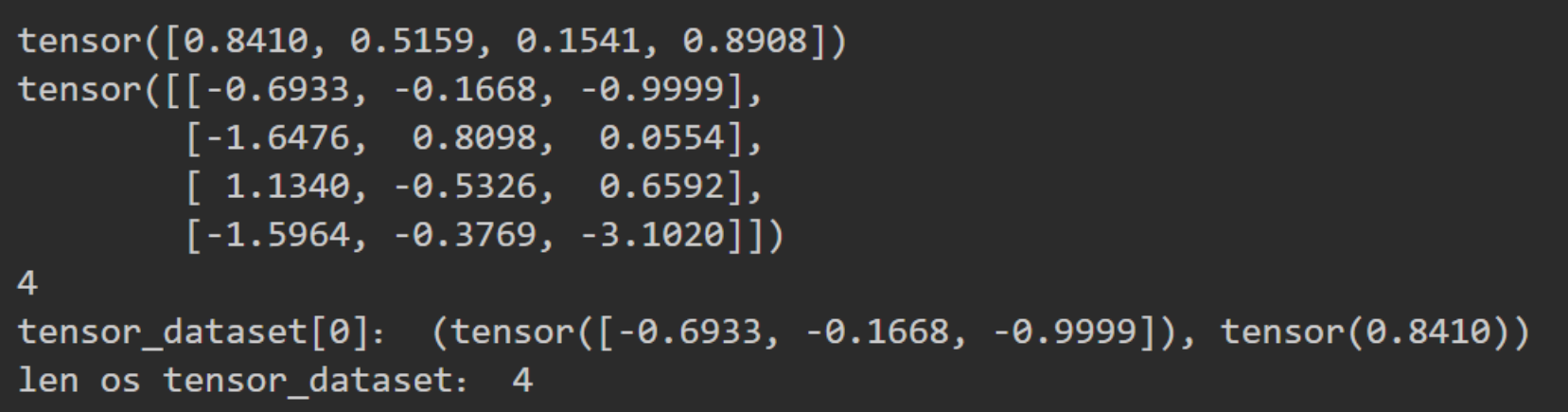
得到的dataset的数据类型是一个元组,元组的每一个对象都是一个tensor数据类型。
1.3 torch.utils.data.sampler
对于可迭代样式的数据集,数据加载顺序完全由用户定义的可迭代样式控制。这样可以更轻松地实现块读取和动态批处理大小(可以每次生成一个批处理的样本)。
pytorch中提供了以下的集中不同方式的数据采样:
- sequential sampler(顺序采样)
- random sampler(随机采样)
- subset random sampler(子随机采样)
- weighted random sampler(加权随机采样)
Squential Sampler
1 | from torch.utils.data import DataLoader,Dataset,Sampler |
random sampler
1 | class RandomSampler(Sampler): |
subset random sampler
1 | class SubsetRandomSampler(Sampler): |
weighted random sampler
1 | class WeightedRandomSampler(Sampler): |
2. sklearn.model_selection
2.1 train_test_split
1 | train_test_split(*array,test_size=0.25,train_size=None,random_state=None,shuffle=True,stratify=None) |
返回切分的数据集train/test,传参是:
- array:切分的数据源
- test_size和train_size:互补和为1的一对值
- shuffle:是否对数据切分之前进行乱序
- stratify:是否分层抽样切分数据
2.2 cross_validate
1 | cross_validate(estimator,X,y=None,groups=None,scoring=None,cv=None,n_jobs=1, |
返回train/test数据集上的每折得分
- estimator:学习器
- X:特征列数据 y:标签列(无监督学习可以无此参数) groups:切分train/test数据集后的样本所在集合标号 scoring:在test数据集上的评估准则(以list/dict形式给出) cv:交叉验证的折数,default=3,也可以是其余int数据,或者cv generator n_jobs:计算执行时占用CPU个数,设置n_jobs=-1是利用全部CPU verbose:设置评估模型的相关打印信息输出详细程度 fit_params:参数字典 pre_dispatch:设置并行任务数(保护内存) return_train_score:返回train数据集上的评估得分
2.3 learning_curve
1 | GridSearchCV(estimator,X,y,groups=None,train_sizes=array([0.1,0.33,0.55,0.78,1.]),cv=None, |
根据设定的不同train数据集大小,依次获得交叉熵验证的train/test数据集上的得分
estimator:学习器 X:特征列数据 y:标签列 groups:切分train/test数据集后的样本所在集合标号 train_sizes:设置训练集数据的变化取值范围 cv:交叉验证的折数,default=3,也可以是其余int数据,或者cv generator scoring:在test数据集上的评估准则(以list/dict形式给出) n_jobs:计算执行时占用CPU个数,设置n_jobs=-1是利用全部CPU pre_dispatch:设置并行任务数(保护内存) verbose:设置评估模型的相关打印信息输出详细程度 shuffle:对数据切分前是否洗牌 random_state:随机种子 exploit_incremental_learning:增量学习
3. torch.nn.utils.rnn
3.1 pack_padded_sequence和pad_packed_sequence
这两个函数主要是为了处理变长序列的padding,一般进行深度学习训练的时候都会分为batch个训练数据一起进行计算,这样会遇到多个训练样例长度不一样的情况,这样就很容易的想到padding,将短的句子padding位跟最长的句子一样。
pack相当于压缩填充过的变长序列,因为填充的时候会有冗余所以要压紧。有了pad的操作之后,padding出现了很多无用的符号,这样得到的句子特征会有误差。pack之后,原来填充PAD的地方就被删除了。输入的形状是\((T \times B \times *)\),T是最长序列的长度,B是batch_size,*代表任意维度。如果batch_first=True的话,那么相应的input size就是\((B \times T \times *)\)。Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后。即input[ : , 0]代表的是最长的序列,input[ : , B - 1]保存的是最短的序列。
1 | embed_input_x_packed = pack_padded_sequence(embed_input_x, sentence_lens, batch_first=True) |
参数:
input(Variable):变长序列,被填充后的batch
lengths(list[int]):variable中每个序列的长度
batch_first(bool,optional):如果是True,input的形状应该是\(B \times T \times size\)
返回值:一个PackedSequence对象。