
RNN与LSTM
RNN模型
RNN模型的结构图如下所示: 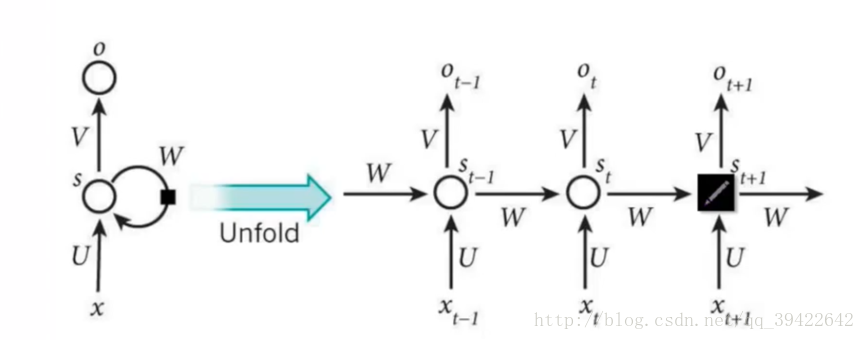 RNN其实是一个单元的重复使用,经常用在与时间序列相关的场景中。这是一种sequential-tosequential的模型。 由网络图可知,每个单元的状态表示为S_t = f(UX_t + WS_(t-1)),f代表的是激活函数。最后输出的是概率预测,使用的是softmax函数。
RNN其实是一个单元的重复使用,经常用在与时间序列相关的场景中。这是一种sequential-tosequential的模型。 由网络图可知,每个单元的状态表示为S_t = f(UX_t + WS_(t-1)),f代表的是激活函数。最后输出的是概率预测,使用的是softmax函数。 
其中U和W都是权重关系,前者称为状态-状态权重,后者称为状态-输入权重. 标准的RNN网络有以下的特点: 1. 权值共享:图中的W全部是相同的,U和V也都一样 2. 每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。
RNN的模型表示: 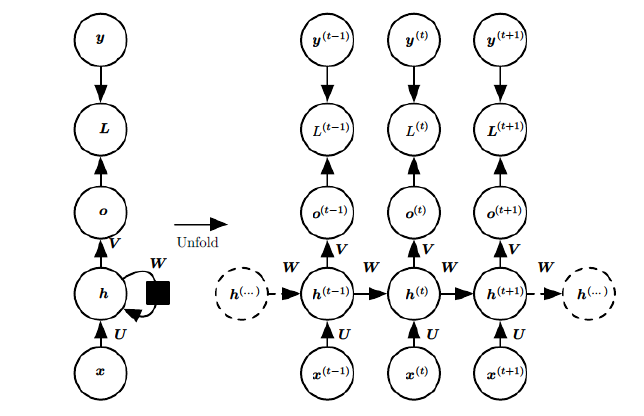 x表示输入,h表示隐层单元,o表示输出,L为损失函数,y为训练集标签。右上角的t表示t时刻的状态。隐层单元在t时刻不仅仅由此时刻的输入决定,还受t时刻之前的时刻的影响。U、W、V是权值,权值共享。 对于t时刻:
x表示输入,h表示隐层单元,o表示输出,L为损失函数,y为训练集标签。右上角的t表示t时刻的状态。隐层单元在t时刻不仅仅由此时刻的输入决定,还受t时刻之前的时刻的影响。U、W、V是权值,权值共享。 对于t时刻: 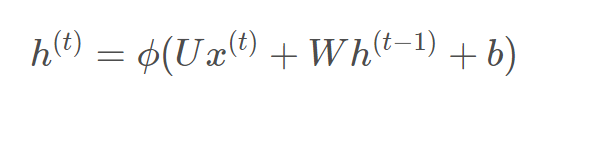 其中fai()是激活函数,一般在RNN里面会选择tanh函数,b为偏置。 t时刻的输出为:
其中fai()是激活函数,一般在RNN里面会选择tanh函数,b为偏置。 t时刻的输出为: 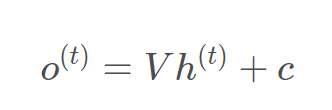 最终的预测模型为:
最终的预测模型为: 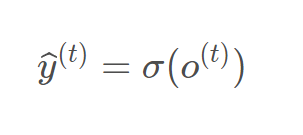 其中σ为激活函数,通常用于分类,为softmmax
其中σ为激活函数,通常用于分类,为softmmax
RNN的训练
BPTT(back-propagation through time)算法是常用训练RNN的方法,核心思想和BP算法相似。需要寻优的参数有三个,分别是U、V、W。W和V的更新都要追溯到历史数据,参数V相对简单只需要关注目前状态,先更新V: 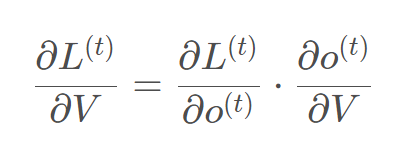 RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。
RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。 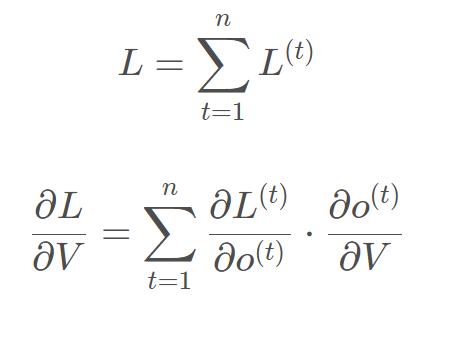 W和U的更新要涉及到历史数据,其偏导求解相对复杂,假设只有三个时刻,那么在第三个时刻L对W的偏导数为:
W和U的更新要涉及到历史数据,其偏导求解相对复杂,假设只有三个时刻,那么在第三个时刻L对W的偏导数为: 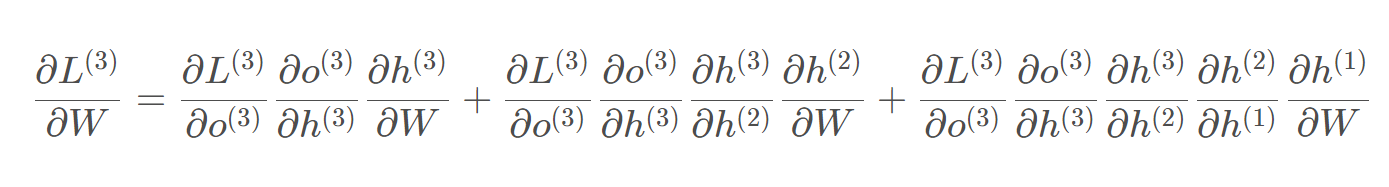 相应的,L在第三个时刻对U的偏导为:
相应的,L在第三个时刻对U的偏导为: 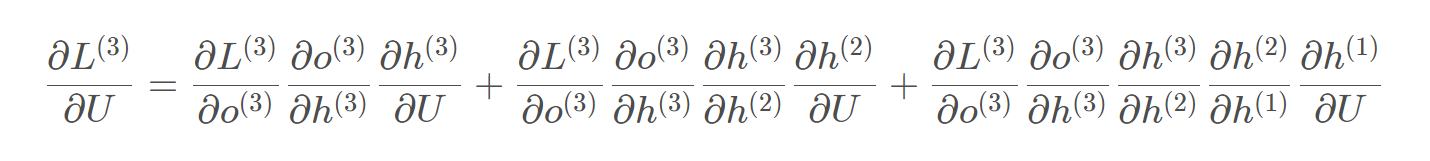 在某个时刻对W或是U的偏导,需要追溯这个时刻之前的所有时刻的信息,那么这个求导的工作将会非常的复杂。但是有规律可循,可以写出L在t时刻对W和U偏导数的通式:
在某个时刻对W或是U的偏导,需要追溯这个时刻之前的所有时刻的信息,那么这个求导的工作将会非常的复杂。但是有规律可循,可以写出L在t时刻对W和U偏导数的通式: 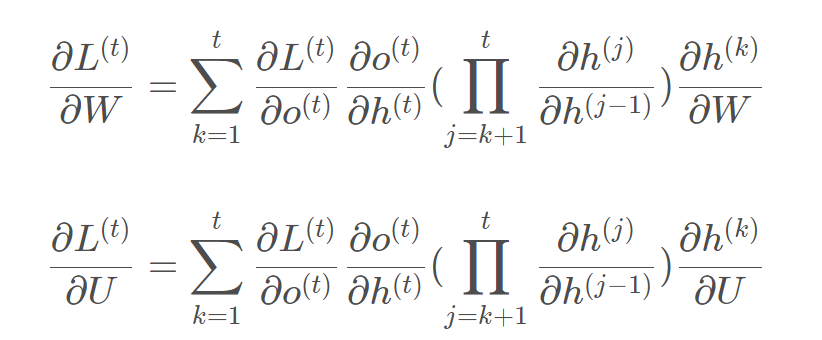 整体的偏导公式就是将其按时刻再一一加起来。 激活函数是嵌套在求导里面的,如果把激活函数放进去,拿出中间累乘的部分:
整体的偏导公式就是将其按时刻再一一加起来。 激活函数是嵌套在求导里面的,如果把激活函数放进去,拿出中间累乘的部分: 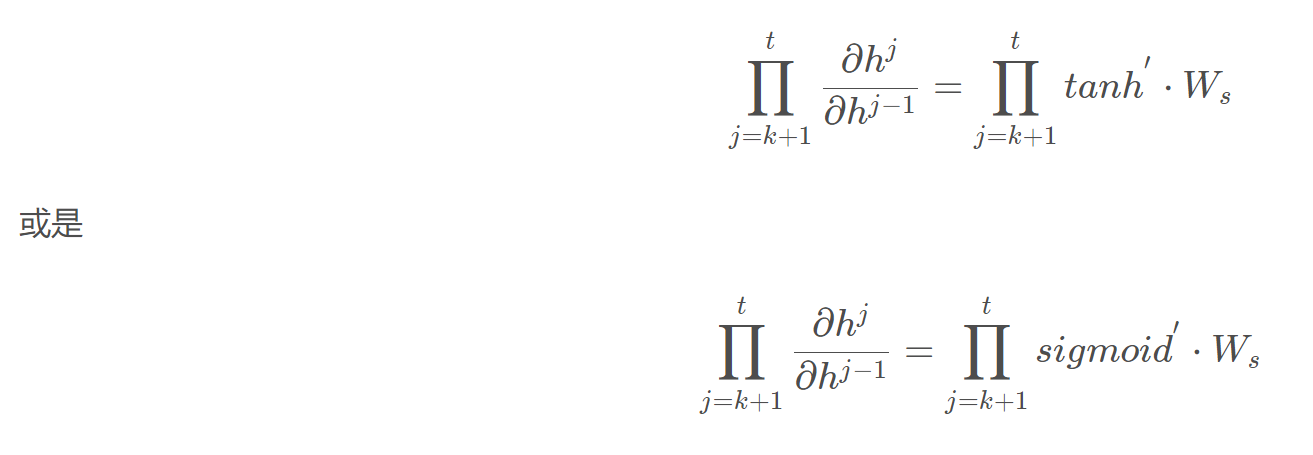 累乘会导致激活函数导数的累乘,进而会导致梯度消失和梯度爆炸的现象发生。
累乘会导致激活函数导数的累乘,进而会导致梯度消失和梯度爆炸的现象发生。
但是RNN具有以下的局限性: * 当时间间隔不断增大的时候,RNN会丧失学习到连接如此远的信息的能力。理论上RNN可以处理长期依赖的关系,人们可以仔细挑选参数来解决这类问题中的最初形式,但是在实践中,RNN肯定不能成功的学习到这些知识。RNN会受到短时记忆的影响。如果一条序列足够长,那它们将很难从将信息从较早的时间步传送到后面的时间步。 因此如果正在1尝试处理一段文本进行预测,RNN可能从一开始就会遗漏重要的信息,在反向传播期间,RNN可能会面临梯度消失的问题。因为梯度用于更新神经网络的权重值,梯度会随着时间的推移不断下降减少,当梯度变得非常小的时候,就不会再学习。在递归的神经网络中,获得小梯度更新的层会停止学习,通常是较早的层。由于这些层不学习,RNN可以忘记它在较长的序列中看到的内容,因此具有短时记忆。而梯度爆炸则是因为计算的难度越来越复杂导致。
LSTM模型
LSTM(Long short-term memory)长短期记忆网络是RNN的一种变体,通过巧妙的门控制将加法运算带入到网络中,缓解了RNN的问题。LSTM模型图如下所示: 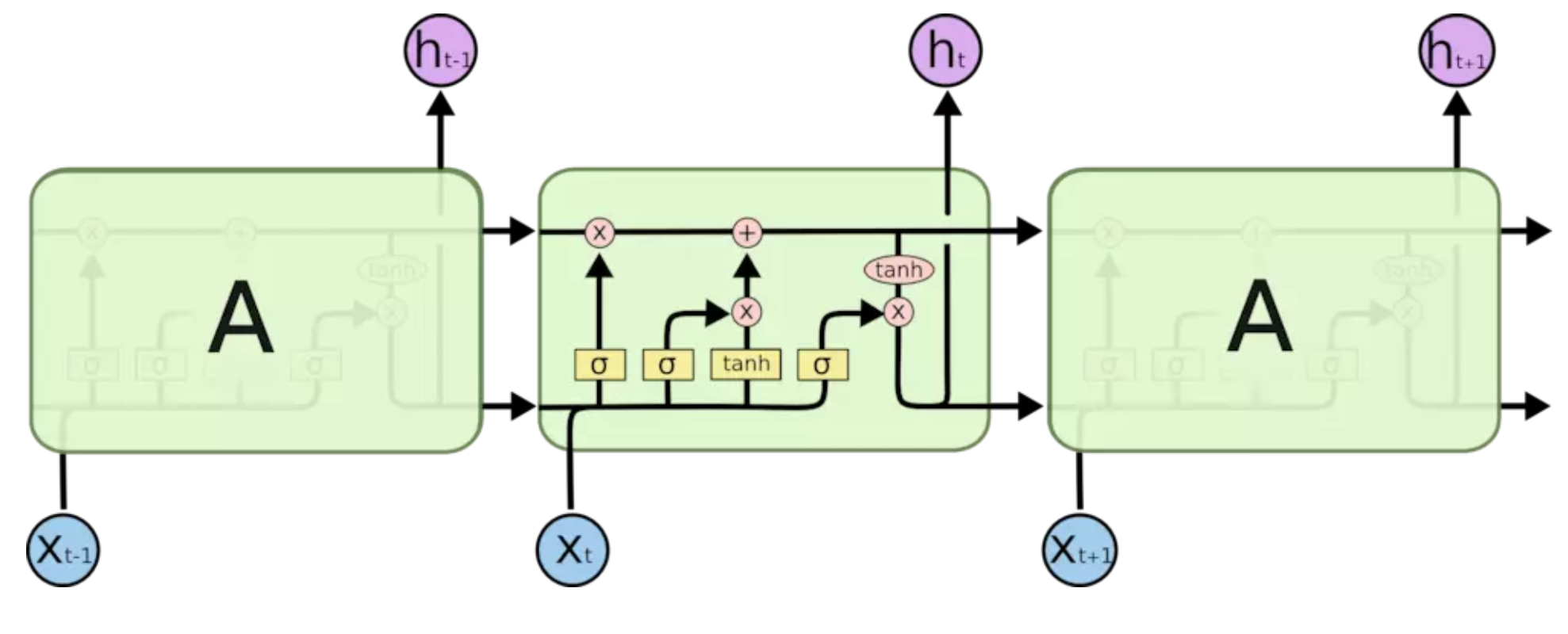 图形的具体含义如下:
图形的具体含义如下: 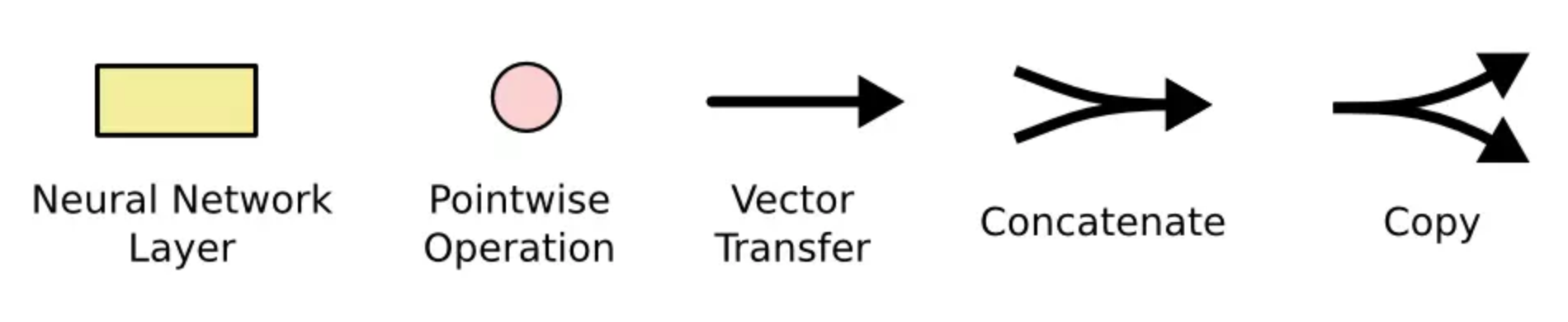 * 黄色的矩形是学习得到的神经网络层 * 粉色的圆形表示一些基本操作,如加法乘法 * 黑色的单箭头表示向量的传输 * 两个箭头合成一个表示向量的连接 * 一个箭头分开表示向量的复制
* 黄色的矩形是学习得到的神经网络层 * 粉色的圆形表示一些基本操作,如加法乘法 * 黑色的单箭头表示向量的传输 * 两个箭头合成一个表示向量的连接 * 一个箭头分开表示向量的复制
LSTM的核心思想
LSTM的关键就是细胞状态1,水平线在图上方贯穿运行。细胞状态类似于传送带,直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。 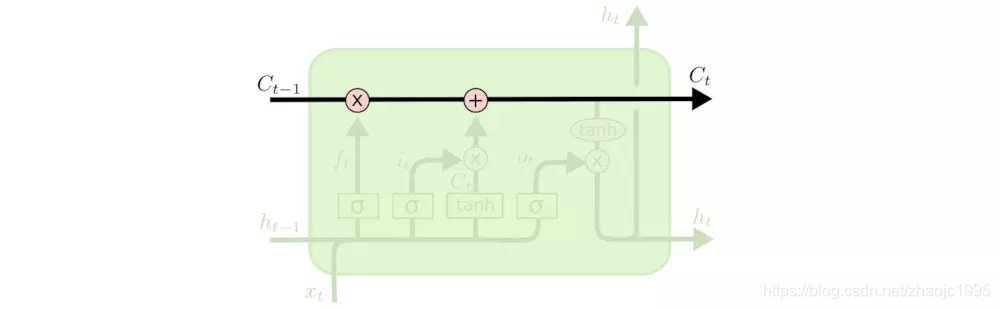 LSTM有通过精心设计的称作“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息有选择的通过的方法,它们包含一个sigmoid神经曾和一个pointwise乘法操作。
LSTM有通过精心设计的称作“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息有选择的通过的方法,它们包含一个sigmoid神经曾和一个pointwise乘法操作。 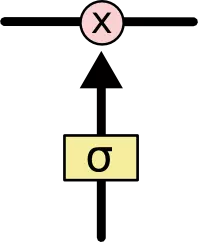 sigmoid输出0-1之间的数值,描述每个部分有多少量可以通过,0代表不允许通过,1代表允许1任何通过,LSTM有三个门,来保护和控制细胞状态。 #### 什么信息会被丢弃? 这个地方要用到第一个门:遗忘门。该门会读取前一个隐藏层的h_t-1和当前输入x_t,输出一个在0-1之间的数值给每个细胞状态C_t-1中的数字。1表示“完全保留”,0表示“完全舍弃”。
sigmoid输出0-1之间的数值,描述每个部分有多少量可以通过,0代表不允许通过,1代表允许1任何通过,LSTM有三个门,来保护和控制细胞状态。 #### 什么信息会被丢弃? 这个地方要用到第一个门:遗忘门。该门会读取前一个隐藏层的h_t-1和当前输入x_t,输出一个在0-1之间的数值给每个细胞状态C_t-1中的数字。1表示“完全保留”,0表示“完全舍弃”。 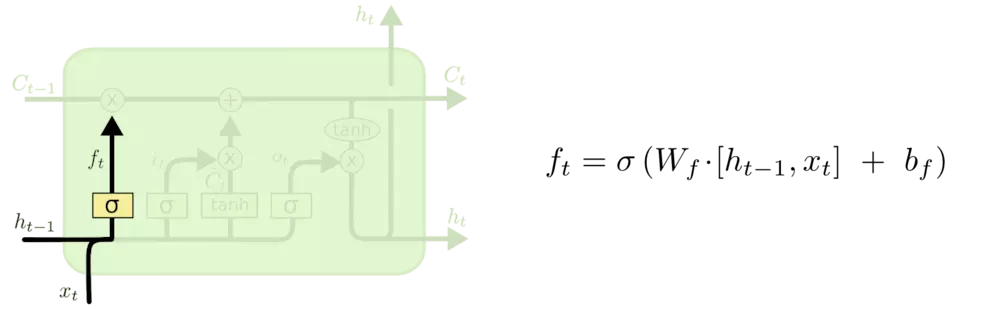 首先,怎么做到遗忘? “遗忘”可以理解为“之前的内容记住多少”,其精髓在于只能输出(0,1)小数的sigmoid函数和粉色圆圈的乘法,LSTM网络通过学习决定让网络记住以前百分之多少的内容。 其次,为啥要遗忘还要接受新的xt? 因为决定记住什么遗忘什么,其中新的输入肯定要产生影响。
首先,怎么做到遗忘? “遗忘”可以理解为“之前的内容记住多少”,其精髓在于只能输出(0,1)小数的sigmoid函数和粉色圆圈的乘法,LSTM网络通过学习决定让网络记住以前百分之多少的内容。 其次,为啥要遗忘还要接受新的xt? 因为决定记住什么遗忘什么,其中新的输入肯定要产生影响。
什么新的消息会被存放在细胞状态中?
这个就叫做“输入门”,包含两个部分:(1)sigmoid层称“输入门层”决定什么值将被更新。(2)tanh层创建一个新的候选值向量,Ct,会被加入到状态中。  现在将要更新新旧细胞状态,Ct-1更新为Ct。把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*Ct,这就是新的候选值,根据我们决定更新每个每个状态的程度进行变化。sigmoid函数选择更新内容,tanh函数创建更新候选。 最终,需要确定输出什么值,这个输出将会基于细胞状态,但是也是一个过滤后的版本。首先,运行一个sigmoid层来确定细胞状态的哪个部分会被输出出去。接着,把细胞状态通过tanh进行处理(得到一个-1到1之间的值)
现在将要更新新旧细胞状态,Ct-1更新为Ct。把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*Ct,这就是新的候选值,根据我们决定更新每个每个状态的程度进行变化。sigmoid函数选择更新内容,tanh函数创建更新候选。 最终,需要确定输出什么值,这个输出将会基于细胞状态,但是也是一个过滤后的版本。首先,运行一个sigmoid层来确定细胞状态的哪个部分会被输出出去。接着,把细胞状态通过tanh进行处理(得到一个-1到1之间的值)  这三个门虽然功能上不同,但在执行任务上的操作时相同的,都是使用sigmoid函数作为选择工具,tanh作为变换工具,这两个函数结合起来实现三个门的功能。
这三个门虽然功能上不同,但在执行任务上的操作时相同的,都是使用sigmoid函数作为选择工具,tanh作为变换工具,这两个函数结合起来实现三个门的功能。
LSTM的变体
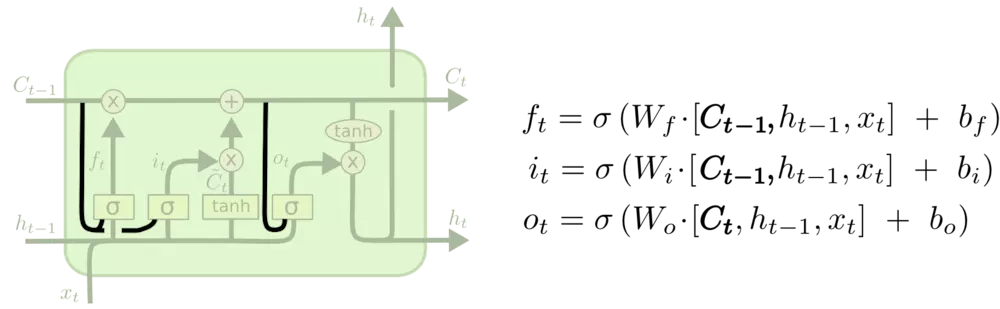 增加了peephole 另一种变体时通过使用coupled忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。仅仅会当将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态。
增加了peephole 另一种变体时通过使用coupled忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。仅仅会当将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态。 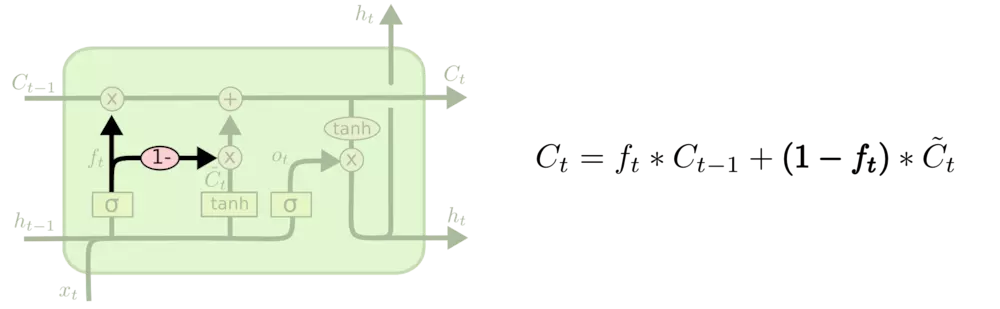 另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。