
Structure Based User Identification across Social Networks
摘要概述
这篇文章介绍的是一种基于结构的用户跨社交网络身份识别模型,目前跨社交网络的可访问性和可靠性大多数基于网络结构,都是需要余弦了解某些特定用户,是受监督或者半监督的。在一些先验知识难以获取的前提下,手工标记先验知识是一项费力的工作。考虑不同的SNs中朋友关系的可靠性和一致性,提出了一种无监督的基于朋友关系的无先验知识用户识别算法(FRUI-P)。算法的思路是:首先将SN中每个用户的好友特征提取为好友特征向量,然后计算两个SNs之间所有相同的候选用户的相似度。最后,提出了一种基于相似度的一对一map识别方法。大量实验结果表明,在没有先验知识的情况下,FRUI-P算法比现有的基于网络结构的算法性能要好得多。由于具有较高的精度,FRUI-P还可以用于生成监督和半监督方案的先验知识。在应用程序中,无监督匿名相同用户识别方法适用于无法获得种子用户的更多场景。
Introduction
首先介绍了社交网络SNs的应用,介绍跨社交网络的用途,跨社交用户的建模可以构建全方位的用户刻画,增加更多的信息。接着介绍了用户识别的概念,跨系统用户身份识别已经获得很多的关注。后来着重介绍前人工作,SNs之间的可访问信息变得越来越碎片化、不一致性和破坏性。这些特点使得传统的解决方案被边缘化,引发了对用户识别新技术的需求。单跟随连接中并不是所有的连接都代表着真正的朋友关系。朋友关系(微博之中的相互关联的关系)更加的可靠和一致,因此更适合跨平台的识别任务。 在该研究中,作者研究了无监督策略,以纯粹的朋友关系识别SNs中的匿名相同用户。在没有规范的情况下,SN的网络结构表示用户之间的朋友关系,忽略单向连接的关系。虽然该算法在现实社交网络中只能识别一部分相同的用户,但它可以与其他无特征的用户识别算法联合应用,获得更高的性能。
本研究的贡献: * 提出了一种新的无监督用户识别算法,即基于朋友关系的无先验知识用户识别(FRUI-P)。它从网络结构中提取每个用户的多维特征,然后从多维特征中评估两个不同SNs中任意两个用户的相似性。与大多数现有方案不同的是,FRUI-P可以在没有显眼只是的情况下识别相同的用户,并为监督和半监督算法提供先验知识。 * 结合环境呈现朋友特征学习的过程。受Word2Vec在自然语言处理的启发,提出了一个利用随机游走能力的朋友特征向量模型(FFVM),虽然Word2Vec在测量任意两个词之间的相似度方面得到了广泛地应用,但是在无监督跨平台任务中的表现尚不清楚。 * 讨论了FRUI-P的效率以及在FRUI-P中确保用户识别性能的策略。证明了FRUI-P在运行时间上比NM(neighbor matching)高效的多。引入三个参数来提高性能,引入一个参数来保证FRUI-P的精度。 * 基于中国的三大合成网络和两个主要的SNs:新浪和人人,对FRUI-P的性能进行了具体的演示。合成的网站包括(erdos renyi ER) 随机网络、Watts-Strogatz(WS)小型世界网络和Barabasi-Albert优先关联模型网站(BA)。
问题定义
术语定义
SN = {U,F},U表示用户集,F表示朋友关系集合,SN表示社交网络,\[SN^A={U^A,F^A}\]表示社交网络A,SN被建模成一个无向图,其中结点和边分别是用户和朋友的关系。在论文中上标表示与SN相关的变量(或符号),下标为SN中的用户。 \[U^A_i\]表示\[SN^A\]中的用户i。具体的术语表示如下图:
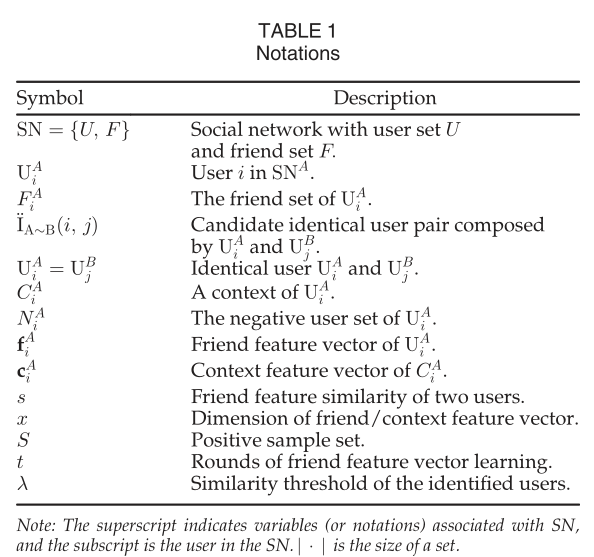
定义1:候选相同用户对 \[U^A_i\]和\[U^B_j\]来自两个不同的社交网络\[SN^A\]和\[SN^B\]形成了候选的相同用户对,记为
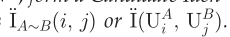 I(.,.)表示所有的用户对,I(\[U^A_i\],.)表示所有的包括社交网络A上的用户i的候选相同用户对。\[|U^A|x|U^B|\]的候选相同用户对存在于I(.,.),\[|U^B|\]存在于\[I(U^A_i)\]
I(.,.)表示所有的用户对,I(\[U^A_i\],.)表示所有的包括社交网络A上的用户i的候选相同用户对。\[|U^A|x|U^B|\]的候选相同用户对存在于I(.,.),\[|U^B|\]存在于\[I(U^A_i)\]定义2:相同用户 对于任意的I(\[U^A_i,U^B_j\]),如果在现实生活中\[U^A_i\]和\[U^B_j\]属于同一个用户,那么这俩就是同一用户,认为他们相等。
定义3:上下文 Ui在社交网络中的上下文文本定义为Ci或者C(Ui), 在研究中,使用随机游走来模拟用户的情景。由于一个用户可能在一个或多个随机游走中出现多次,因此一个用户可能有多个上下文。我们预测Ui有着更高的概率预测Ui而有着更低的概率预测Uj。
定义4:良性抽样 在一个社交网络中,对于一个给定的Ci,(Ci,Ui)是一个良性的sample。所有的正样本构成正样本集S
定义5:负用户集,负样本 与正样本的定义相反,除Ui外的其他用户,记做Ni或者N(Ui)被定义为Ci的负用户集,因此Ni=U-{Ui},对于任意的用户Uj属于Ni,(Ci,Uj)组成了负样本。
定义6:朋友特征向量 对于任意的用户,他的friend feature向量fi是一个x维向量,嵌入了他的朋友的特征,x是预先给定的参数。
定义7:朋友特征相似度 任何一个I(UA_i,UB_j)的相似度为两个用户在朋友特性上的相似性,表示为s(UA_i,UB_j).由于朋友特征被表示为friend feature vector,s(UA_i,UB_j)被测定为fA_i和fB_j
问题定义
在现实世界中,每个人都有自己的朋友圈,这是高度个人化的。因此,如果我们知道一个人的所有朋友,我们可能知道他/她是谁。 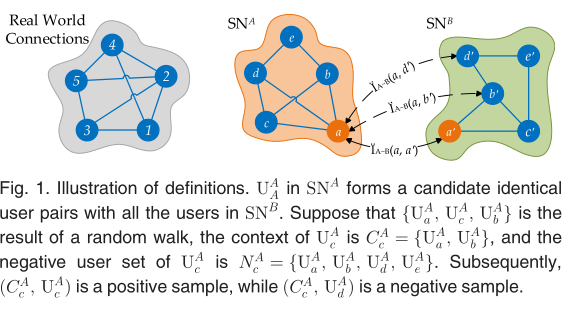 假设人们在现实世界中是随机建立友谊,任何两个人之间建立友谊的概率是P(0~1)。s_a和s_b分别是友谊存在于SNA和SNB中的概率。因此,在SNA和SNB中存在友谊的概率是Pxs_a和Pxs_b,将一段友谊在SNA和SNB中都存在的概率定义为Pxs_axs_b。随后,当UA_i=UB_j时,UA_i和UB_j共享|U|xPxs_axs_b个朋友,或者|U|xPxs_axs_b,|U|就是社交网络中的用户数量。显然,在UA_i=UB_j和U^_I!=U^B_j之间,共享好友的差异是1/p倍。这为纯粹使用网络结构的跨平台用户识别奠定了基础。 跨平台用户识别问题是判断UA_i和UB_j在两个不同额度社交网络AB之间是否为同一个用户,它被定义为
假设人们在现实世界中是随机建立友谊,任何两个人之间建立友谊的概率是P(0~1)。s_a和s_b分别是友谊存在于SNA和SNB中的概率。因此,在SNA和SNB中存在友谊的概率是Pxs_a和Pxs_b,将一段友谊在SNA和SNB中都存在的概率定义为Pxs_axs_b。随后,当UA_i=UB_j时,UA_i和UB_j共享|U|xPxs_axs_b个朋友,或者|U|xPxs_axs_b,|U|就是社交网络中的用户数量。显然,在UA_i=UB_j和U^_I!=U^B_j之间,共享好友的差异是1/p倍。这为纯粹使用网络结构的跨平台用户识别奠定了基础。 跨平台用户识别问题是判断UA_i和UB_j在两个不同额度社交网络AB之间是否为同一个用户,它被定义为 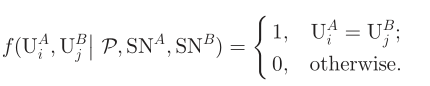
这里面的P是先验知识,或者额外的信息,除了SNA和SNB外预先给定的。比方说,P就是FRUI的种子用户。当没有其他可用的额外信息时,P=φ。在这个场景中,只有朋友关系可以被利用,并且(2)变成 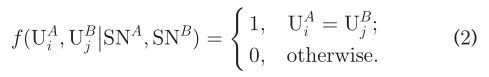 显然,f(.)是我们在本研究中寻求的功能。由于各种原因,有些人在同一个SN中存在着多个账户,但我们通常认为这些多个账户是独立的,属于不同的个人。换句话说,我们只确定了其中一个账户。(这里不太赞同和理解***)
显然,f(.)是我们在本研究中寻求的功能。由于各种原因,有些人在同一个SN中存在着多个账户,但我们通常认为这些多个账户是独立的,属于不同的个人。换句话说,我们只确定了其中一个账户。(这里不太赞同和理解***)
相关工作
这一章里面作者主要从基于概要、基于内容和基于网络结构三个方面综述了跨平台用户识别的研究现状,并对网络嵌入进行了简要总结。 ### profile-based user identification 个人的profile界面上有公共个人资料:包括用户名、性别、生日、城市和个人资料形象。在几乎所有SNs中,用户名都是公共必须的配置文件特性。公共profile属性为用户标识提供了强大的信息,然而在大规模SNs中,有些属性是重复的,很容易被模拟出来。 ### content-based user identification 这个方法就是根据用户发布内容的时间和地点,以及内容的写作风格来识别用户。地理位置具有强大的用户识别功能,但是在社交网络中,这类信息很少,因为只有一小部分用户愿意发布自己的位置。 ### network structure-based user identification #### network structure-based user identification with prior knowledge 基于网络结构的先验知识可分为两类:监督模型和半监督模型。 #### network structure-based user identification without prior knowledge 这里作者首先简要介绍了NM的工作。 假设两个社交网络SNs都有n个用户,SNA和SNB,NM首先定义了一个相似度s(UA_i,UB_j)。最开始,s(0)(UA_i,UB_j)=1,NM会反复地更新相似度的数值。在第k次的迭代中,NM构造了一个完全二部图B(K+1)_i,j=(FA_i,FB_j,FA_ixFB_j),其中每一个边界(U^A'_i,U^B'_j)权重为s(k)(UA'_i,U^B'_j)。最终,NM找到B^(k+1)_i,j的最大权值匹配,定义为M^(k+1)_i,j,并且更新s(i,j)为: 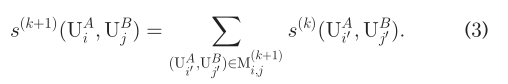 当s归一化收敛之后,NM返回的是B=(UA,UB,UAxUB)的最大加权匹配的top m映射,每次迭代的整体运行时间是O(n2d3_max),其中d_max是用户好友数量的上限。SN多次被验证为无标度的网络,因此,d_max≈n并且SN中NM的时间复杂度为O(n^5)。虽然NM在去匿名化的任务中是有效的,但是时间复杂度很高,在两个SNs不保证重叠的情况下还没有得到验证。 图内核方法从两个图中找到相似的子图,并与用户识别任务相关。但是图核解决方案主要集中于计算子图的相似度。
当s归一化收敛之后,NM返回的是B=(UA,UB,UAxUB)的最大加权匹配的top m映射,每次迭代的整体运行时间是O(n2d3_max),其中d_max是用户好友数量的上限。SN多次被验证为无标度的网络,因此,d_max≈n并且SN中NM的时间复杂度为O(n^5)。虽然NM在去匿名化的任务中是有效的,但是时间复杂度很高,在两个SNs不保证重叠的情况下还没有得到验证。 图内核方法从两个图中找到相似的子图,并与用户识别任务相关。但是图核解决方案主要集中于计算子图的相似度。
本文中的FRUI-P与之前的研究的不同之处在于: * 1 FRUI需要先验知识,而FRUI-P和NM不需要。FRUI-P解决了获得匹配的相同用户的问题。在没有先验知识的情况下,单纯使用网络结构来衡量两个SNs中两个用户的相似度几乎是不可能的。NM通过一个相似度迭代过程来解决这个问题,而FRUI-P从网络结构中提取朋友特征向量来评估相似度。 * 2 NM适用于去匿名化的任务,而FRUI-P和FRUI侧重于不同SNs上的用户识别。虽然这三种算法都能在两个不同的网络中找到相同的用户,但NM实际上工作在相同你的SN上。 * 3 FRUI-P和FRUI可以在异构SNs上运行,朋友关系是稳定的,可靠的和一致的SNs。FRUI和FRUI-p都将不同SNs中的连接转换为好友关系,并通过好友关系识别相同的用户。 * 4 FRUI-P比NM更高效。我们证明了FRUI-P的运行时间复杂度为O(n2),而NM的成本为O(n5)。显然,FRUI-P在用户识别任务中的成本要低得多。 * 5 FRUI-P可以很容易地以并行的方式实现,而NM不能。 * 6 FRUI-P在内存空间中运行O(xn),而NM需要O(n^2),其中x是一个小整数,表示友元特征向量的维数。因此,FRUI-P可以应用于更大的SNs。
network embedding
网络嵌入的目的是学习网络中定点的潜在表示。
user identification without prior knowledge
通常,当两个给定用户的相似性大于某个阈值时,这两个用户是相同的。因此跨平台用户识别的关键在于找到在两个给定网络中的任意在I(.,.)中的item。给定足够的相同用户作为先验知识,可以使用许多解决方案来定义和评估候选相同用户的相似性。但是,在没有先验知识的情况,评价任意两个用户的相似度任然是一项具有挑战性的任务。为了解决社交网络去匿名化领域的这个问题,NM通过迭代过程预计了所有I(.,.)中的item的相似性。在一定程度上,NM只是利用了用户网络的一种特性。从直观上看,NM的表现可以通过施加多维特征加以提高。 对于现实世界中的任意个体i,如果他的朋友关系特征可以被提取并嵌入到向量f_i中,那么他在SNA和SNB中的朋友特征向量fA_i和fB_j一定是相似的,因为个人在不同的SNs中部署了相似的朋友关系。以图2为例,由于个人1在SNA和SNB中有相似的朋友,如果我们将个人1以及他在SNA中的账户UA_a和在SNB中的账户UB_a'转换为二维向量,他们必须在几何上紧密地定位,也就是说在二维空间上fA_a和fB_a'几乎在同一个点上。 基于非监督好友关系的用户识别算法的关键技术可以分为两类:用户好友特征向量模型(FFVM)和基于特征向量的用户识别模型。
朋友特征向量模型
维数的限制和嵌入特征的无用使传统的相邻顶点无法方便的识别问题,因此,主要的任务是指定朋友特征向量。深度学习允许由多个处理层组成的计算模型学习具有多个抽象层的数据表示,其有效性已在多个领域得到验证。我们还使用深度学习的力量来抽象朋友特征向量。我们的算法采用了随机游走,并且是在word2vec上的方法之上。如图所示,FFVM由正样本模型和朋友特征向量学习模型两部分组成。
4.1.1 Positive Sample Model
正样本模型的目的是生成给定SN地正样本集合S。由于Ci对Ui的预测概率较高,因此可以从Ci中提取出Ui的特征。随机漫步的威力已经在多个领域得到验证,在本研究中,我们使用简单随机游走(SRW)来构建正样本模型。因为启动结点上存在重启(RWR)偏差,节点上存在较大程度的Metropolis-Hasting随机游走(MHRW)偏差。 在随机漫步的开始,一个随机用户U_i1被选择为根据用户并设置为当前用户。然后遍历一个随机的用户Ui2∈Fi1并将其设置为当前用户。按照这个程序,随机漫步(Ui1,Ui2,...)当l>0个用户被覆盖。由于朋友有更多的能力来预测一个用户,而那些建立在另一个用户之上的潜在联系在会引入噪音,所以在这项研究中只有朋友被考虑。随后,给定一个随机游走(...,U_ik-1,U_ik,U_ik+1,...),C_ik={U_ik-1,Uik+1}。显然,每个随机游走可以生成两个正样本。最后,用近似|S|/l个随机游走过程产生S。显然,S应该足够大以确保能够正确提取给定SN中每个用户的好友特征。值得注意的是,在随机漫步中允许重复的用户,因此这些有声望的用户将在随机漫步中出现多次。 以图1b为例,(UA_a,UA_c,UA_b,UA_d,UA_b)是一个随机游走的结果。对于一个用户UA_c,我们有CA_c={UA_a,UA_b}和NAc包含于{UA_a,UA_b,UA_d,UA_e}。因此,(CA_c,UA_c)是一个positive的样本,但(CA_a,U^A_b)是一个negative的样本。正样本模型为朋友特征向量学习模型奠定了基础。 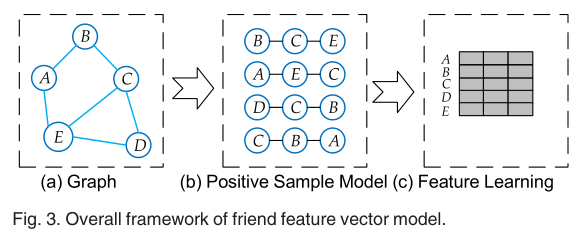 #### 4.1.2 friend feature vector learning model
#### 4.1.2 friend feature vector learning model
朋友特征向量学习模型学习给定SN中的任意U_i的f_i(用户特征)。在本研究中,我们在NLP中使用了基于负采样的CBOW模型。在一开始,定义: 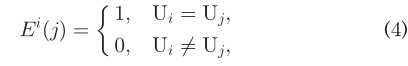 其中,U_i和U_j是在给定SN中的两个用户。 这里使用极大似然法建立最有函数,对于给定的positive样本(C_i,U_i),我们有:
其中,U_i和U_j是在给定SN中的两个用户。 这里使用极大似然法建立最有函数,对于给定的positive样本(C_i,U_i),我们有: 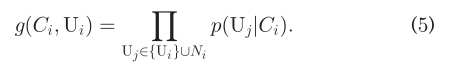 在本研究中,我们使用s行函数来定义p(U_j|C_i)
在本研究中,我们使用s行函数来定义p(U_j|C_i) 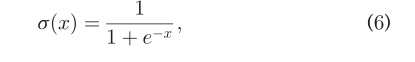 我们有:
我们有: 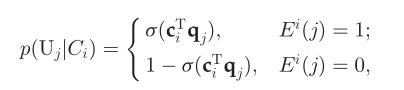 其中q_j∈Rx是U_j的一个辅助参数,cT代表c的转置,c_i∈R^x是f_j的求和U_j∈C_i
其中q_j∈Rx是U_j的一个辅助参数,cT代表c的转置,c_i∈R^x是f_j的求和U_j∈C_i  公式7也可以被如下表示:
公式7也可以被如下表示: 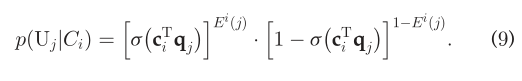 因此,(5)转换为:
因此,(5)转换为: 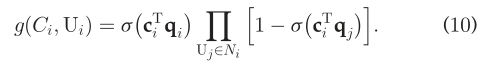 显然的是,σ(c^T_iq_i)表示C_i正确预测U_i的概率,而σ(cT_iq_j),U_J∈N_i表示C_i正确预测用户U_j的概率。因此,对于任意的C_i,我们都希望最大化,σ(c^T_iq_i)并且最小化σ(cT_iq_j)。因此,tuidao推导出最优函数(10) 同样,给定S,极大似然函数,即全局的最优函数如下:
显然的是,σ(c^T_iq_i)表示C_i正确预测U_i的概率,而σ(cT_iq_j),U_J∈N_i表示C_i正确预测用户U_j的概率。因此,对于任意的C_i,我们都希望最大化,σ(c^T_iq_i)并且最小化σ(cT_iq_j)。因此,tuidao推导出最优函数(10) 同样,给定S,极大似然函数,即全局的最优函数如下: 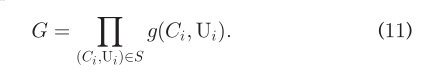 为了降低计算复杂度,我们通过去对数来转换(11),因此我们有:
为了降低计算复杂度,我们通过去对数来转换(11),因此我们有: 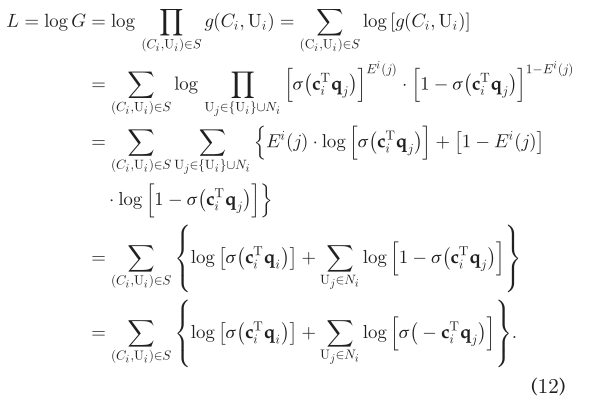 优化目标采用异步随机梯度算法。令:
优化目标采用异步随机梯度算法。令: 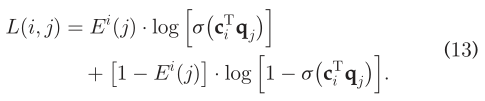 使用:
使用: 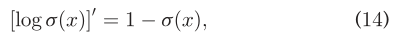 并且:
并且: 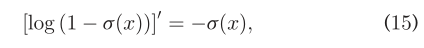 我们有:
我们有: 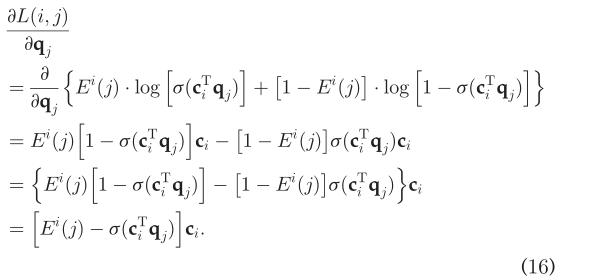 因此,q_j的更新方程是:
因此,q_j的更新方程是: 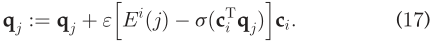 其中ε是学习率。更高的ε可以是q_j收敛更快,但是效率更低。类似的,根据q_j和c_i的对称性,我们有:
其中ε是学习率。更高的ε可以是q_j收敛更快,但是效率更低。类似的,根据q_j和c_i的对称性,我们有: 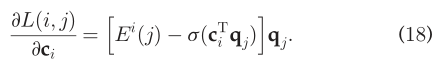 由于c_i是f_v,U_v∈C_i的求和,c_i的梯度可以直接提供f_v的更新。随后,更新f_v的等式为:
由于c_i是f_v,U_v∈C_i的求和,c_i的梯度可以直接提供f_v的更新。随后,更新f_v的等式为: 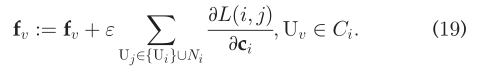 不幸的是,发现(19)在计算上是昂贵的。因为(19)需要对在N_i所有的用户集合求和,近似等于U。为了解决这一问题,我们采用噪声对比估计(NCE)方法,根据每个用户Ui的某些噪声,对多个negative情况进行抽样。这个过程也被称为负采样(NEG),冰杯证明是有掉的学习高质量向量表示。具体来说,N_i被NEG(U_i)如下:
不幸的是,发现(19)在计算上是昂贵的。因为(19)需要对在N_i所有的用户集合求和,近似等于U。为了解决这一问题,我们采用噪声对比估计(NCE)方法,根据每个用户Ui的某些噪声,对多个negative情况进行抽样。这个过程也被称为负采样(NEG),冰杯证明是有掉的学习高质量向量表示。具体来说,N_i被NEG(U_i)如下: 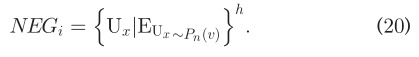 其中,{.}h表示{.}的数量,h是每个数据集的negative样本。任务是使用逻辑回归从噪声分布P_n(v)中区分目标用户U_i的样本。我们令P_n(v)∝d(3/4)_v,如文献54中提出来的,其中n=|U|表示SN中的所有用户,并且d_v是F_v的小。因此,每个用户的目标函数可以转换为:
其中,{.}h表示{.}的数量,h是每个数据集的negative样本。任务是使用逻辑回归从噪声分布P_n(v)中区分目标用户U_i的样本。我们令P_n(v)∝d(3/4)_v,如文献54中提出来的,其中n=|U|表示SN中的所有用户,并且d_v是F_v的小。因此,每个用户的目标函数可以转换为: 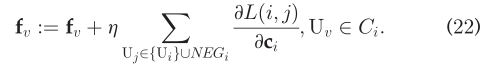 第一项模型观察用户,而第二项反映负样本从噪声分布。随后,(19)变成:
第一项模型观察用户,而第二项反映负样本从噪声分布。随后,(19)变成: 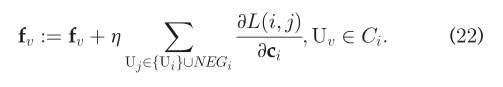 算法1总结了FFVM的整个过程。第二行生成所有用户的负样本,第三行为每个用户初始化随机值f_i和q_i,第四行生成整样本S。第5-14行迭代每个正样本并更新f_i和q_i,第15行返回所有用户的好友特征。
算法1总结了FFVM的整个过程。第二行生成所有用户的负样本,第三行为每个用户初始化随机值f_i和q_i,第四行生成整样本S。第5-14行迭代每个正样本并更新f_i和q_i,第15行返回所有用户的好友特征。 
4.2 基于朋友特征向量的用户识别
基于两个已知社交网络中的每个用户的好友特征向量,可以利用多个指标来评估所有的在I(.,.)中所有items的相似度,比如说欧几里德距离,切比雪夫距离,余弦。在这里,我们认为相同用户的朋友特征向量比非相同用户的朋友特征向量更接近。因此我们使用欧几里得距离来评价在I(.,.)中items的相似性。为了归一化相似度,我们有: 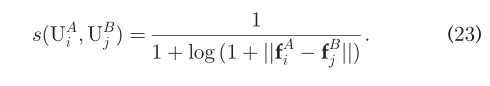 用户识别问题通常转化为二部匹配问题。不同于完美匹配问题或完全匹配问题,用户识别寻求一种稳定的匹配。因为我们只考虑一个人在一个SN中拥有一个账户的情况,并且相同的用户比其他用户拥有最相似的朋友特征向量。因此,如果UA_i=UA_j,那么s(UA_i,UB_j)相较于s(UA_i,.)和s(.,UB_j)是不会更少的。因此,无需先验知识的用户识别函数可求解为
用户识别问题通常转化为二部匹配问题。不同于完美匹配问题或完全匹配问题,用户识别寻求一种稳定的匹配。因为我们只考虑一个人在一个SN中拥有一个账户的情况,并且相同的用户比其他用户拥有最相似的朋友特征向量。因此,如果UA_i=UA_j,那么s(UA_i,UB_j)相较于s(UA_i,.)和s(.,UB_j)是不会更少的。因此,无需先验知识的用户识别函数可求解为 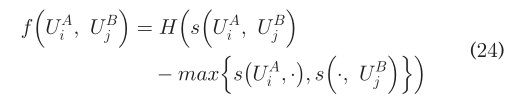 其中max{.}返回的是{.}的最大值,并且s(UA_i)返回的是在I(UA_i,.)中所有的items的相似度。H(y)是Heaviside阶跃函数,定义如下:
其中max{.}返回的是{.}的最大值,并且s(UA_i)返回的是在I(UA_i,.)中所有的items的相似度。H(y)是Heaviside阶跃函数,定义如下: 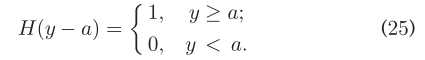 显然,没有先验知识的用户识别是一项具有挑战性的攻击任务。在某些场景中,一轮特性学习过程可能不足以确保性能。用f^(t1)表一个用户的t1个朋友特征向量,(23)可以被概括为:
显然,没有先验知识的用户识别是一项具有挑战性的攻击任务。在某些场景中,一轮特性学习过程可能不足以确保性能。用f^(t1)表一个用户的t1个朋友特征向量,(23)可以被概括为: 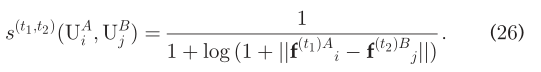 其中,1<=t1,t2<=t。为了降低运行时间的复杂性,我们简化(24)为:
其中,1<=t1,t2<=t。为了降低运行时间的复杂性,我们简化(24)为: 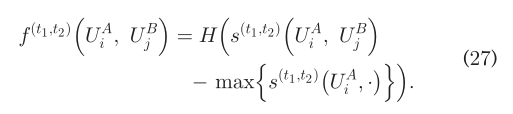 每个SN对应t个特征矩阵,t2次用户识别,由t2对特征矩阵组合得到的结果被执行。对于每一对,只有那些在I(.,.)中的items满足f(.,.)=1的被保留。注意到相同的用户出现了好几次,我们总结了它们的相似之处。最后,定义相似度为
每个SN对应t个特征矩阵,t2次用户识别,由t2对特征矩阵组合得到的结果被执行。对于每一对,只有那些在I(.,.)中的items满足f(.,.)=1的被保留。注意到相同的用户出现了好几次,我们总结了它们的相似之处。最后,定义相似度为 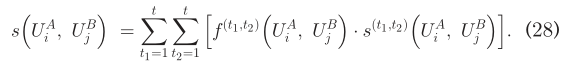 此外,(24)用于确保一对一的映射。 可想而知,只有几个朋友的用户的朋友特性是很难了解的。它实际上是直观的,因为这些用户的有限上下文可以表述出来。随后,为了提高精度,相似性和朋友的大小都应该考虑。此处,我们对每个在I中的item更新s(.,.) 这里min{.}返回{.}的最小值。只有在I(.,.)中的items满足s(.,.) λ>=0才被认为是同一个用户。随后,我们有:
此外,(24)用于确保一对一的映射。 可想而知,只有几个朋友的用户的朋友特性是很难了解的。它实际上是直观的,因为这些用户的有限上下文可以表述出来。随后,为了提高精度,相似性和朋友的大小都应该考虑。此处,我们对每个在I中的item更新s(.,.) 这里min{.}返回{.}的最小值。只有在I(.,.)中的items满足s(.,.) λ>=0才被认为是同一个用户。随后,我们有: 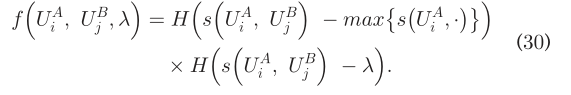 算法2给出了FRUI-P。第2行启动参数。第3行和第4行学习每个节点的好友特征向量。第5-9行更新所有节点对的相似性。第10行确保了一一映射,并返回相似度大于λ的相同用户。
算法2给出了FRUI-P。第2行启动参数。第3行和第4行学习每个节点的好友特征向量。第5-9行更新所有节点对的相似性。第10行确保了一一映射,并返回相似度大于λ的相同用户。 
4.3 讨论
- 引理1:FFVM的时间复杂度是O(|U|)+O(|S|xx^2),其中|U|,|S|和x分别为SN中的用户数、正样本数和朋友特征向量的维数。
- 证明:negative采样的产生是O(|U|)。由于|S|positive采样要求大约|S|随机选择结点或者其临近结点,随机游走过程的时间复杂度为O(|S|)。在FFVM中的8-14行是对于每个(C_i,U_i)的过程,并且时间复杂度是O(|NEG_i|x x2),其中|NEG_i|表示在NEG_i中用户的个数。因此,FFVM的总的复杂度是O(|U|)+O(|S|)+O(|S|x|NEG_i|xx2)=O(|U|)+O(|S|xx^2),因为|NEG_i|是一个小整型数。 虽然FFVM也从朋友关系中学习用户的潜在朋友表示,但它与目前的网络嵌入解决方案不同。我们以DeepWalk[47]作为比较,因为它的进程类似于FFVM。首先,在建模S时只考虑朋友,因为建立在另一个用户之上的底层连接会在识别用户时引入噪声[28]。然而,为了模拟全局网络特征,DeepWalk包含了大量未连接的用户。第二,FFVM中使用了CBOW, DeepWalk中使用了SkipGram[39]。最后,为了加快训练时间,FFVM使用了负采样,而DeepWalk使用了层层化的Softmax。
- 定理1:FRUI-P的总的时间复杂度是O(tmax{|SA|,|SB|}x2)+O(t2*max{|UA|,|UB|}2),其中t,|UA|,|UB|,|SA|,|S^B|和x分别为好友特征学习的次数、sna和SNB中的用户数量、sna和SNB的正样本数量、好友特征向量的维数。t轮朋友特征向量学习的时间复杂度为 avatar FRUI-P中的第7-8行计算I(.,.)中每个items中的相似度并且f(.,.)=1和在时间复杂度的花费O(|UA||UB|)。因此,行5-8的时间复杂度是O(t2|UA||UB|)。由于行9的花费不大于O(|UA||UB|),FRUI-P的总的时间复杂度是O(tmax{|UA|,|UB|})+O(tmax{|SA|,|SB|}x2)+O(t2|UA||UB|)+O(|UA||UB|)=O(tmax{|SA|,|SB|}x2)+O(t2max{|UA|,|UB|}2) 显然,较大的t会增加FRUIP的复杂度,但也保证了FRUI-P的查全率和查准率。更多的正样本确保充分学习朋友特征向量,更大的x意味着考虑更多维度的特征。增加S或x会提高FRUI-P的复杂性,但可以提高用户识别的性能。我们的实证研究也证实了t、S和x可以提高FRUI-P的绩效。λ保证识别用户的最小相似度,并确保精度。既然相同用户的相似度小于λ错过了,高λ结果找回率较低。当λ=0,所有识别出的用户均视为相同用户。 由于在实际中|S|>=|F|,并且|S|<=|U|2,我们大约设O(|S|)=O(|U|2)。因此,FRUI-P的时间复杂度可简化为 avatar 注意到FFVM中的f_i和q_i的更新没有获取一个锁来访问共享参数。这允许我们在多工作器的情况下是使用一部随机梯度算法,并帮助实现最优的手链策略。而且,(26)和(27)可以以并行的方式工作。因此,FRUI-P的并行版本易于实现,从而使FRUI-P具有可伸缩性。
{kind=link}
{kind=link}
实验研究
我们在合成和地面真实网络中验证了FRUI-P。所有实验均使用8G内存和2.8 GHz CPU的计算机进行。
我们使用NM作为主要基线,因为它是最接近FRUI-P的一种先进的、基于网络结构的非监督算法,该算法在WSDM 2013数据挑战[38]的去匿名任务中获得了一等奖。在我们的NM经验测试中,图的大小不超过1000个节点。由于NM的运行时间和空间要求,分别是O(n5)和O(n2),限制了NM的可扩展性。例如,一对有50,000个节点的图,NM要求不少于50000x50000x4Bx2(NM使用kth和(k+1)th相似度矩阵)=20G内存,超过了设备的能力。 FRUI是本研究的另一个对手,因为它是纯使用网络结构的最先进的半监督用户识别技术。 我们采用召回率、准确率和F1-measure来衡量性能。它们被定义为  更高的查全率、精度和F1-measure表明用户识别方案的性能更好。 除了真实世界的实验,我们还在合成网络上进行了大量的实验来评估FRUI-P的性能。SNs在用户(节点)和好友(边缘)[28]中自然是重叠的。节点重叠是所有用户识别方案的基本假设,而边缘重叠是所有基于网络结构的算法的基础。为了实现不同程度的节点和边缘重叠,我们添加了不同程度的噪声图。对于给定的网络,通过保持每个节点/边具有一定的抽样概率来生成子网。经过两轮采样过程,产生一对子网,两个子网中保持的共同节点是相同的。图4给出了图解。我们引入了Jaccard系数来度量节点/边重叠的程度,
更高的查全率、精度和F1-measure表明用户识别方案的性能更好。 除了真实世界的实验,我们还在合成网络上进行了大量的实验来评估FRUI-P的性能。SNs在用户(节点)和好友(边缘)[28]中自然是重叠的。节点重叠是所有用户识别方案的基本假设,而边缘重叠是所有基于网络结构的算法的基础。为了实现不同程度的节点和边缘重叠,我们添加了不同程度的噪声图。对于给定的网络,通过保持每个节点/边具有一定的抽样概率来生成子网。经过两轮采样过程,产生一对子网,两个子网中保持的共同节点是相同的。图4给出了图解。我们引入了Jaccard系数来度量节点/边重叠的程度, 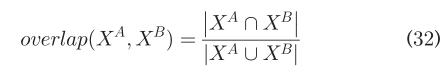 其中,overlap(.,.)表示X的重叠程度,X表示两个图的U/F。因此,当两个图每一个都共享2/3的结点,overlap(UA,UB)=0.5,边缘重叠程度受重叠节点之间关系的限制。
其中,overlap(.,.)表示X的重叠程度,X表示两个图的U/F。因此,当两个图每一个都共享2/3的结点,overlap(UA,UB)=0.5,边缘重叠程度受重叠节点之间关系的限制。
5.1 合成网络实验
为了验证FRUI-P的性能,我们在ER[40]随机网络、WS[41]小世界网络和BA[42]网络中进行了实验。三种合成网络的性质参照了我们之前的研究[28]。ER和WS网络都是由规则随机网络以一定的概率重新布线每条边而产生的。如果所有的边都重新布线,使得重新布线的概率等于1,那么这个网络就是一个ER网络;否则为WS网络。在实验中,WS网络中重接线的概率为0.5。
我们在实验中生成了75对网络来说明FRUI-P在合成网络中的性能。在这三个合成网络实验中,总共创建了5个5000个节点的网络。在5个ER和WS网络实验中,两个节点之间存在一条边的概率p分别为0.02、0.04、0.06、0.08和0.1。同样,在BA网络实验中,连接一个新节点到现有节点的边数m从20增加到100,增加了20。随后,由15个合成网络产生75对网络,overlap(UA,UB)=1并且overlap(FA,FB)等于0.25,0.36,0.49,0.64和0.81.我们在所有实验中设置t=1,λ=0,|S|=50|F|并且x=500。值得注意的是,在我们的实验中,所有的边缘都是随机采样的,这可以更准确地模拟现实世界的SNs。这种随机抽样也描述了跨平台用户识别任务和去匿名任务之间的差异,这两个SNs在一堆节点上完全重叠。 ER网络实证检验结果如表2所示。 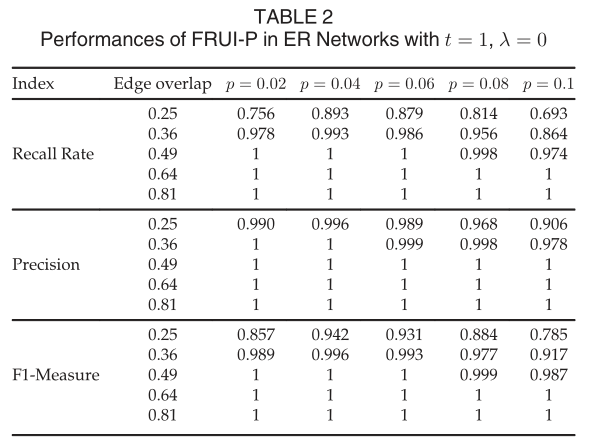 随着两种SNs边缘重叠程度的增加,FRUI-P的性能有所提高。同样值得注意的是,FRUI-P识别几乎所有相同的结点当overlap(FA,FB)>=0.49.此外,所有25对网络的精度均大于90%。FRUI-P在WS网络中的性能如表3所示。与在ER网络中的实验类似,FRUI-P识别不少于90%的所有相同用户当overlap(FA,FB)>=0.36,所有25对网络的准确率都大于96.3%。结果表明,FRUI-P在WS网络中的性能要优于ER网络。表4的结果显示,FRUI-P在BA网络中也表现良好。
随着两种SNs边缘重叠程度的增加,FRUI-P的性能有所提高。同样值得注意的是,FRUI-P识别几乎所有相同的结点当overlap(FA,FB)>=0.49.此外,所有25对网络的精度均大于90%。FRUI-P在WS网络中的性能如表3所示。与在ER网络中的实验类似,FRUI-P识别不少于90%的所有相同用户当overlap(FA,FB)>=0.36,所有25对网络的准确率都大于96.3%。结果表明,FRUI-P在WS网络中的性能要优于ER网络。表4的结果显示,FRUI-P在BA网络中也表现良好。 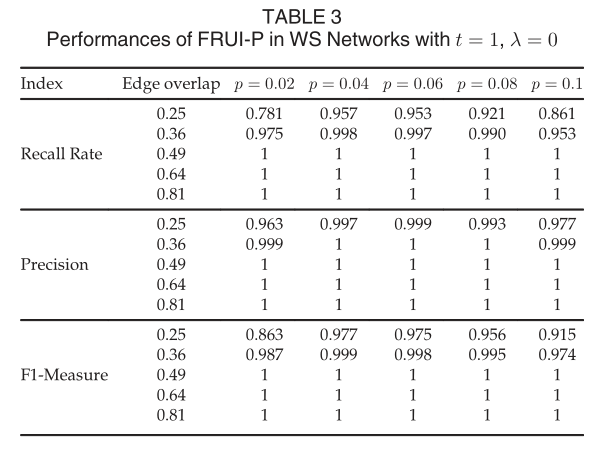 虽然在BA网络中,FRUI-P的性能不如在ER和SW网络中,但在同一时间内,其精度均大于91.5%当overlap(FA,FB)>=0.49.此外,当m>=40时,几乎所有被识别的用户都是正确的。并且几乎所有相同的用户在overlap(FA,FB)>=0.64时均被识别。毫无疑问,通过增加x、t和|S|,可以进一步提高FRUI-P在BA网络中的性能,如第5.2节所验证。在所有ER、WS和BA网络上的实验中,FRUI-P发现了几乎所有相同的节点当overlap(FA,FB)>=0.64,这与现实世界的社交网络大致相同。这表明FRUI-P可以在没有种子用户的情况下处理用户标识任务。同时,精度几乎为1当overlap(FA,FB)>=0.49,这验证了FRUI-P可以用于为其他一些用户识别算法生成先验知识,例如FRUI
虽然在BA网络中,FRUI-P的性能不如在ER和SW网络中,但在同一时间内,其精度均大于91.5%当overlap(FA,FB)>=0.49.此外,当m>=40时,几乎所有被识别的用户都是正确的。并且几乎所有相同的用户在overlap(FA,FB)>=0.64时均被识别。毫无疑问,通过增加x、t和|S|,可以进一步提高FRUI-P在BA网络中的性能,如第5.2节所验证。在所有ER、WS和BA网络上的实验中,FRUI-P发现了几乎所有相同的节点当overlap(FA,FB)>=0.64,这与现实世界的社交网络大致相同。这表明FRUI-P可以在没有种子用户的情况下处理用户标识任务。同时,精度几乎为1当overlap(FA,FB)>=0.49,这验证了FRUI-P可以用于为其他一些用户识别算法生成先验知识,例如FRUI 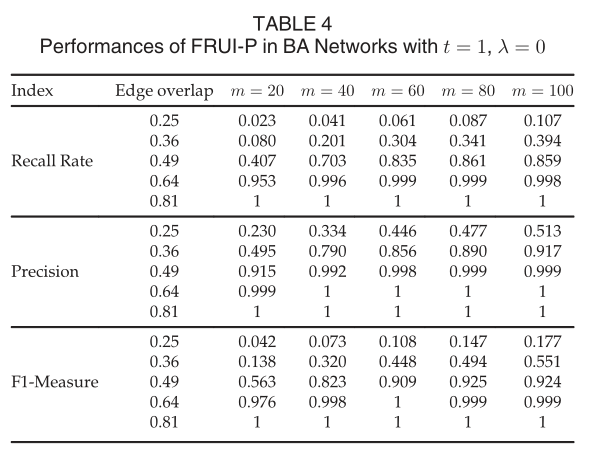
我们还对FRUI- p、FRUI和NM的有效性进行了实验比较。三种合成网络中FRUI- p、FRUI和NM的比较如图5所示。我们改变overlap(FA,FB)的值从0.25-1在实验之中。在ER和WS网络中p=0.02,并且在BA网络中m=20。我们使用具有5000个节点的图来评价FRUI- p、FRUI和NM。FRUI的先验知识为50。由于召回率、precision和F1-Measure在实验中呈现相同的趋势,只有召回率被证明。ER模型和WS模型生成的网络实验结果如图5a和5b所示。显然,在ER和WS网络中FRUI- p和FRUI识别出几乎所有相同的节点当overlap(FA,FB)>=0.36时。三种算法在BA网络中的召回率如图5c所示。FRUI- p和FRUI都具有良好的性能,尤其是当overlap(FA,FB)>=0.64。相比之下,当,NM识别所有相同的节点当overlap(FA,FB)几乎是1,如果没有什么区别的话,当overlap(FA,FB)<=0.81,在这三个合成网络中。这意味着当两个图被随机抽样时,NM执行不充分。因此,当两个SNs重叠在65%左右时,我们可以采取NM不能应用于跨平台用户识别任务的态度。 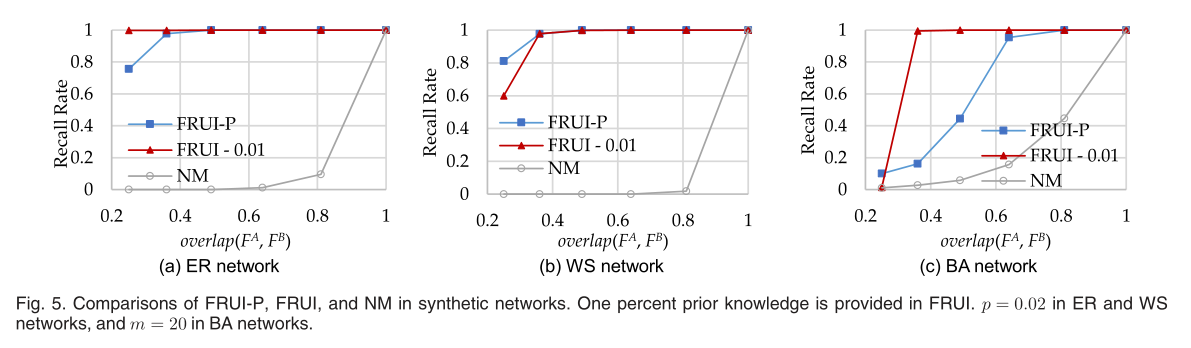 此外,还比较了FRUI- p和FRUI之间的微妙差别,在三种合成网络中均具有overlap(FA,FB)=0.25,如图6所示。我们比较了50个和100个匹配的相同用户作为先验知识的FRUI- p和FRUI。显著的是,在WS和BA网络中,当预先给出一小部分相同用户时,FRUI- p的性能优于FRUI。
此外,还比较了FRUI- p和FRUI之间的微妙差别,在三种合成网络中均具有overlap(FA,FB)=0.25,如图6所示。我们比较了50个和100个匹配的相同用户作为先验知识的FRUI- p和FRUI。显著的是,在WS和BA网络中,当预先给出一小部分相同用户时,FRUI- p的性能优于FRUI。 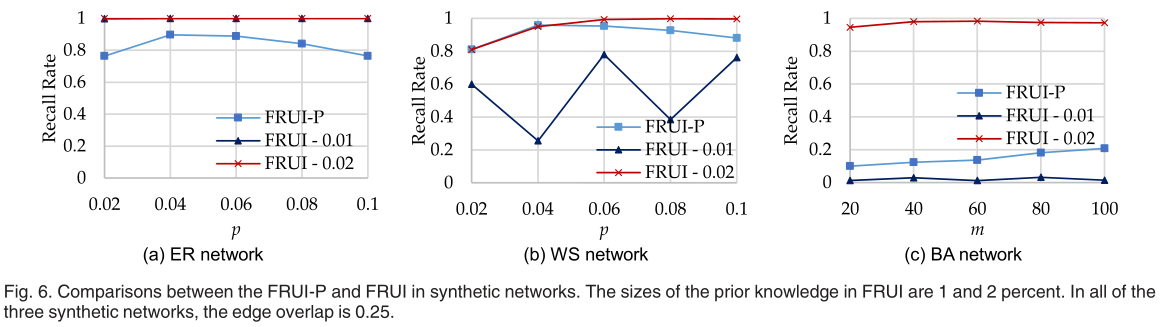
5.2 参数的影响
x、|S|和t三个参数可以提高FRUI-P的性能,而λ被引入来保证FRUI-P的高精度。本节将验证四个参数的效果。不规范,overlap(FA,FB)=0.64.x=500,|S|=50|F|,t=1,λ=0在这个部分。 作为对三种合成网络的实证检验,FRUI-P几乎识别出了ER和WS网络中所有相同的节点。因此,我们只在BA网络上进行了进一步的实验,以显示这些参数对FRUI-P的影响。 由于增大|S|可以为朋友特征学习提供更多的正样本,我们通过10jFj的步长将|S|从30|F|变化到70|F|来观察正样本数对FRUI-P的影响。图7a和7b的结果显示,阳性样本越多,可以保证更多的相同用户,精度越高。我们还将x从100变化到900,以200步来评估x对FRUIP的影响。如图7c和7d所示,x越大,查全率越高,查准率也越高。 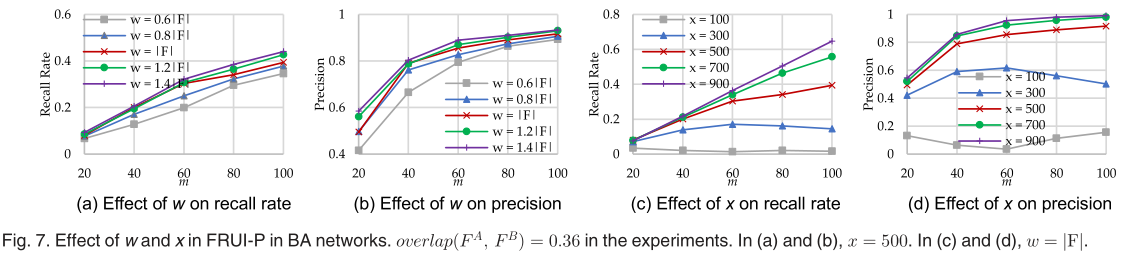 在overlap(FA,FB)=0.49时的实验结果如图8a所示,召回率随着t的增加而增加。换句话说,t越高,用户越相同,无论网络是多么稀疏还是稠密。图8b显示的结果显示了m = 60时t的影响。无论这两个SNs之间有多少重叠,高t也能保证更多相同的用户。 当m=60并且overlap(FA,FB)=0.36时的实验结果如图8c和图8d所示。图8c给出了精度与λ之间的关系。显然,精确度随着λ的增加而增加,当λ=1时,几乎所有的用户都被识别出来。我们还提出了精度和召回率之间的权衡以及λ在图8 d。说明准确率的提高可能会导致召回率的下降。值得注意的是,即使在特殊情况下,FRUI-P也能以不低于95%的精度识别20%的相同用户。这证明了FRUI- p有能力为其他解决方案(例如FRUI)提供先验知识。
在overlap(FA,FB)=0.49时的实验结果如图8a所示,召回率随着t的增加而增加。换句话说,t越高,用户越相同,无论网络是多么稀疏还是稠密。图8b显示的结果显示了m = 60时t的影响。无论这两个SNs之间有多少重叠,高t也能保证更多相同的用户。 当m=60并且overlap(FA,FB)=0.36时的实验结果如图8c和图8d所示。图8c给出了精度与λ之间的关系。显然,精确度随着λ的增加而增加,当λ=1时,几乎所有的用户都被识别出来。我们还提出了精度和召回率之间的权衡以及λ在图8 d。说明准确率的提高可能会导致召回率的下降。值得注意的是,即使在特殊情况下,FRUI-P也能以不低于95%的精度识别20%的相同用户。这证明了FRUI- p有能力为其他解决方案(例如FRUI)提供先验知识。 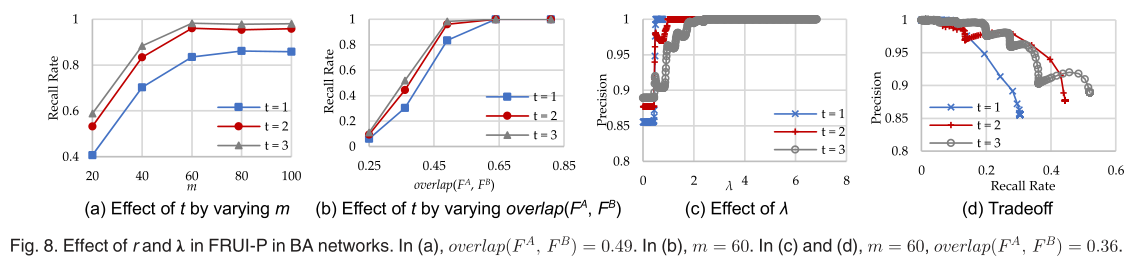
5.3 社交网络实验
在本节中,我们使用地面真实数据集来评估用户识别分辨率。为了验证不同类型的社交网络,我们从新浪微博和人人网这两个异构的社交网络中收集数据。新浪微博拥有117万用户和190万好友关系,人人网拥有550万用户和1460万好友关系。更多数据集的细节可以在我们之前的研究[24]中找到。为了评估真实数据集的FRUI-P性能,我们生成了一系列受控数据集。我们从这两个SNs中选择了一对子图,每个子图都有超过50,000个节点。 在这个实验之中,我们随机选择了一些共享节点作为先验相等的FRUI用户,并且对于FRUI-P t=1,λ=0,x=500并且|S|=50|F|。然后,我们在FRUI- p和FRUI中执行用户标识。我们将所有相同用户中先验相同用户的百分比从0.01增加到0.1,增加的步长是0.01。由于新浪微博和人人网的平均度都比较低,所以只选择邻居不小于u的节点作为重叠节点。为了验证FRUI-P的表现,我们把u从20增加到100,每次增加20。虽然只选择好友在你以上的用户,但抽样后,度分布也遵循幂律分布。也就是说,在抽样的社交网络中,有很多(如果不是大多数)好友数低于5的用户,这些用户很难识别。 图9比较了新浪和人人网络中FRUI- p和FRUI的召回率。在FRUI中,1%和8%的相同用户是先验知识。尽管FRUI显示了更好的性能,但FRUI- p也能够识别所有相同用户的20%左右,而无需事先知道这些相同用户。此外,在θ=20的SNS中,FRUI- p比FRUI发现更多的相同用户,而在FRUI中只有1%的先验知识。在真实社交网络中,FRUI-P的表现并不像在合成网络中那样令人满意,因为在这些真实社交网络中,几乎有一半的用户只有一个朋友,而这些朋友的特征几乎不可能从他们的朋友那里了解到。 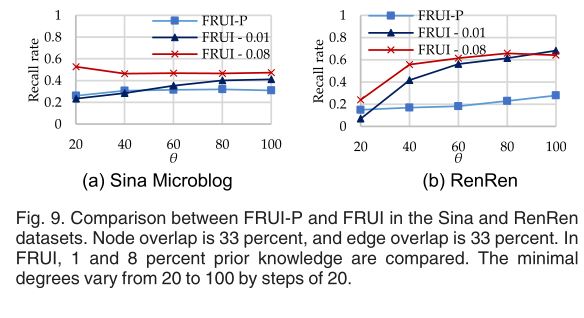 我们还考察了在FRUI-P中的朋友数量和λ该方法适用于解释FRUI-P在现实SNs中的性能。在u = 100的SNs中,精确好友数的趋势如图10a所示。显然,FRUI-P的精度随着朋友数的增加而增加。同时,对于好友数在60以上的用户,其识别精度在80%以上,表明FRUI-P识别好友数较多的用户具有较高的识别精度,验证了好友数较少的用户的好友特征很难学到。此外,当用户在新浪有超过120个好友,在人人网有超过250个好友时,几乎所有的用户都是相同的。精度随λ的变化趋势如图10b所示。与合成网络实验相似,λ越高,识别结果的精度就越高,并且精度达到0.9当λ=0.4同时在sina和人人网上。准确率和召回率之间的权衡如图10c所示。很明显,在新浪和人人网,FRUI-P以95%的精确度回报了15%以上的相同用户。如之前[21]的研究所示,只有一小部分的先验知识,例如1%,可以帮助识别新浪数据集中40%以上的相同用户和人人数据集中60%以上的相同用户。因此,FRUI- p可以是FRUI的强大补充,因此FRUI- p可以用于为那些需要先验知识的算法提供先验知识。
我们还考察了在FRUI-P中的朋友数量和λ该方法适用于解释FRUI-P在现实SNs中的性能。在u = 100的SNs中,精确好友数的趋势如图10a所示。显然,FRUI-P的精度随着朋友数的增加而增加。同时,对于好友数在60以上的用户,其识别精度在80%以上,表明FRUI-P识别好友数较多的用户具有较高的识别精度,验证了好友数较少的用户的好友特征很难学到。此外,当用户在新浪有超过120个好友,在人人网有超过250个好友时,几乎所有的用户都是相同的。精度随λ的变化趋势如图10b所示。与合成网络实验相似,λ越高,识别结果的精度就越高,并且精度达到0.9当λ=0.4同时在sina和人人网上。准确率和召回率之间的权衡如图10c所示。很明显,在新浪和人人网,FRUI-P以95%的精确度回报了15%以上的相同用户。如之前[21]的研究所示,只有一小部分的先验知识,例如1%,可以帮助识别新浪数据集中40%以上的相同用户和人人数据集中60%以上的相同用户。因此,FRUI- p可以是FRUI的强大补充,因此FRUI- p可以用于为那些需要先验知识的算法提供先验知识。 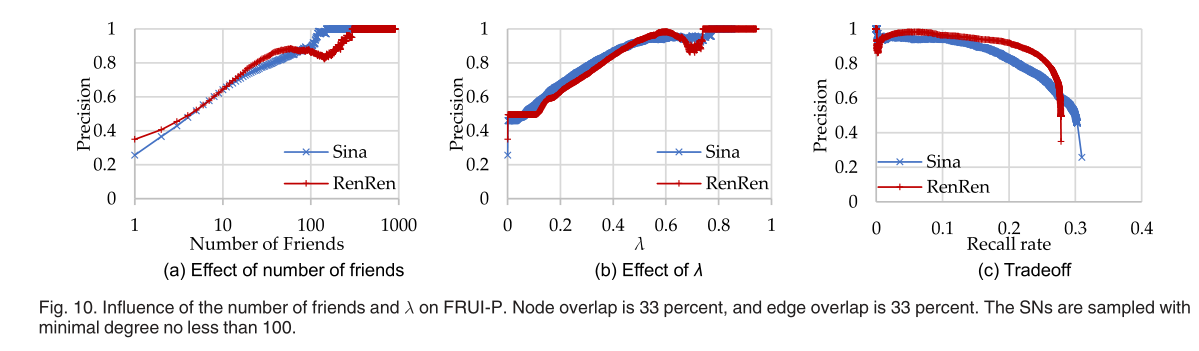 我们还通过三组实验评估了FRUI-P在新浪微博和人人网用户识别中的性能。在每个实验中,我们从中国人民大学(RUC)的相同用户出发,选择一对子图,采用广度优先搜索提取两层朋友。删除叶节点,只留下具有RUC教育背景的用户。由于相同用户的确切数量是未知的,所以只比较精度。当λ=0时,FRUI-P返回的相同用户几乎和NM一样多。这里我们选择了300个相似度最高的用户来检测FRUI-P和NM的精度,实证结果见表5,在三个实验中,FRUI-P的精度都在80%左右,优于NM。这些发现表明,FRUI-P在识别新浪微博和人人网上的相同用户方面更为熟练。 最后,我们联合使用FRUI- p和FRUI进行了实验。选取FRUI- p相似度最高的150个用户作为FRUI的先验知识。我们随机选择300名识别用户检查准确性。实证结果表明,通过联合使用FRUI- p和FRUI,约有一半的被识别用户是相同的。所识别的用户总数和精度如表5所示。结果表明,FRUI-P可用于监督或半监督方案的先验知识获取。
我们还通过三组实验评估了FRUI-P在新浪微博和人人网用户识别中的性能。在每个实验中,我们从中国人民大学(RUC)的相同用户出发,选择一对子图,采用广度优先搜索提取两层朋友。删除叶节点,只留下具有RUC教育背景的用户。由于相同用户的确切数量是未知的,所以只比较精度。当λ=0时,FRUI-P返回的相同用户几乎和NM一样多。这里我们选择了300个相似度最高的用户来检测FRUI-P和NM的精度,实证结果见表5,在三个实验中,FRUI-P的精度都在80%左右,优于NM。这些发现表明,FRUI-P在识别新浪微博和人人网上的相同用户方面更为熟练。 最后,我们联合使用FRUI- p和FRUI进行了实验。选取FRUI- p相似度最高的150个用户作为FRUI的先验知识。我们随机选择300名识别用户检查准确性。实证结果表明,通过联合使用FRUI- p和FRUI,约有一半的被识别用户是相同的。所识别的用户总数和精度如表5所示。结果表明,FRUI-P可用于监督或半监督方案的先验知识获取。 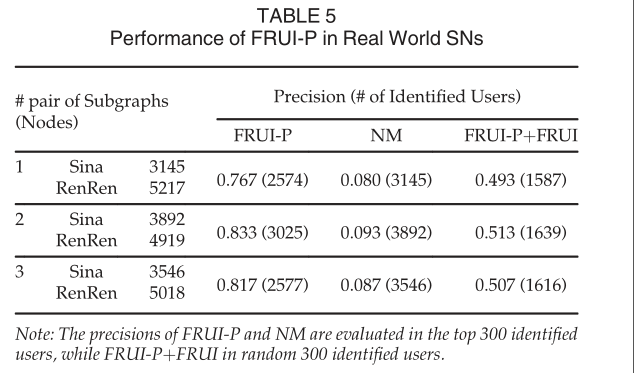
结论
本研究解决了跨SN平台的用户身份识别问题,提供了一种创新的解决方案。网络结构作为网络序列号的一个关键方面,对解决用户识别问题至关重要。许多研究报告称,相同的用户在不同的SN平台上有相似的朋友。因此,我们提出了一种基于统一网络结构的用户识别解决方案。基于我们之前的研究[28],我们开发了一个新的无监督的基于朋友关系的算法称为FRUI-P。我们还讨论了其复杂性和可伸缩性。最后,我们在合成网络和ground-truth网络中验证了我们的算法。 实验结果表明,该网络结构能够完成重要的用户识别任务。我们的FRUI-P算法效率高,性能比NM算法好得多。在原始文本数据稀疏、不完整或由于隐私设置而难以获取的情况下,FRUIP非常适合跨平台任务。此外,FRUI- p可以为许多基于先验知识的用户识别方案(如FRUI)提供可靠的先验知识。由于FRUI-P的并行版本易于实现,所以我们的方法是可伸缩的,可以很容易地应用于大型数据集。为了提高效率,我们将在未来的工作中探讨对另一个图上的每个节点缩小候选相同节点的预处理过程。显然,没有先验知识的匿名相同用户识别方法适用于难以获得种子用户的更多场景,因此在很大程度上增强了适用性。 跨多个SNs识别匿名用户是一项具有挑战性的工作。因此,只能使用此方法识别具有不同别名的部分相同用户。本研究为进一步研究这一问题奠定了基础。最终,我们希望能够开发出一种最终的方法,以在理想情况下识别所有具有不同昵称的相同用户。其他用户识别方法可以同时用于检测多个SN平台。这些方法是互补的,而不是相互排斥的,因为最终的决策可能依赖于人类用户的参与。因此,我们建议协同应用这些方法,并适当利用其优势,应导致有利于其共同目标的最佳效果